Practicalities of Malicious Models
Background
 This is about how I felt reading a couple of recent pieces about discovering malicious models on Huggingface.
This is about how I felt reading a couple of recent pieces about discovering malicious models on Huggingface.
There’s been a steady increase in the amount of posts raising awareness of malicious models, which is cool. It’s also been fun seeing some of my payloads make it into the articles. The posts offer up a lot of really good model-focused solutions to the problem of malicious models, which is great. Obviously we want to find malicious models and encourage safetensor usage.
The reality is, making a malicious model isn’t the goal - it’s just the first step. The goal is to mess with your stuff. Since its just a program, its reasonable to expect that pretty much no matter what places like HuggingFace do, there will be little malicious programs or poisoned backdoors running inside some model formats for folks to call out on their platform, probably forever.
Let’s look at some of the other ways Huggingface can make using malicious models harder:
In my original disclosure of my TTPs that allowed me to not just create malicious models, but use them practically, in bug bounty, and red teaming. I tried to focus on solutions that made life as an attacker hard by calling out all the things that made it easy. I’m less concerned with malicious models existing as I am the actual interface and user experiences that make malicious models feasible attack vectors, and not just random files in a enormous repository of models that will never get executed.
What are the things that make malicious models feasible as an attack chain?
The number one thing that makes this attack path feasible is the way that organizations in Hugging Face work.
- Organization Confusion aka namespace squatting
- Misleading engineers into joining organizations that are not controlled by their employer, resulting in the attacker gaining read/write on all uploaded repositories.
This category of attacks is the single most effective way I’ve found to get malicious models infront of people. Here are the reasons why:
Any user, from any email domain, can create an organization with any unique name they wish:

That user can then email anyone in that company and they will receive an email from Huggingface inviting them.
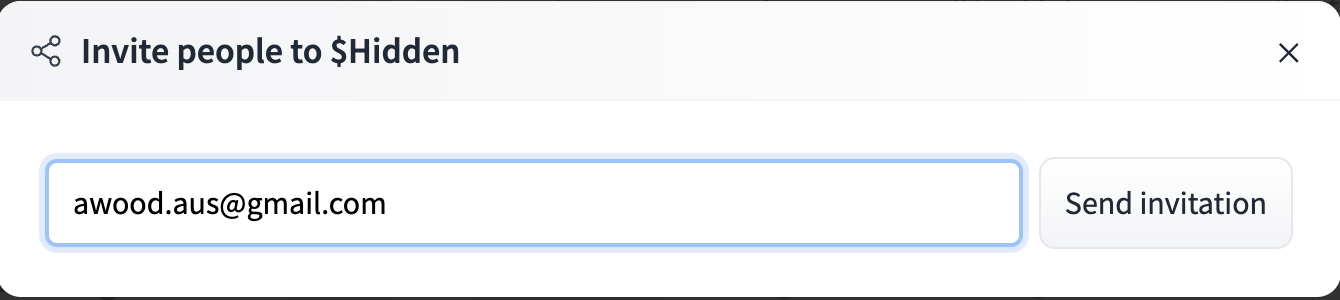 Out goes the invite
Out goes the invite
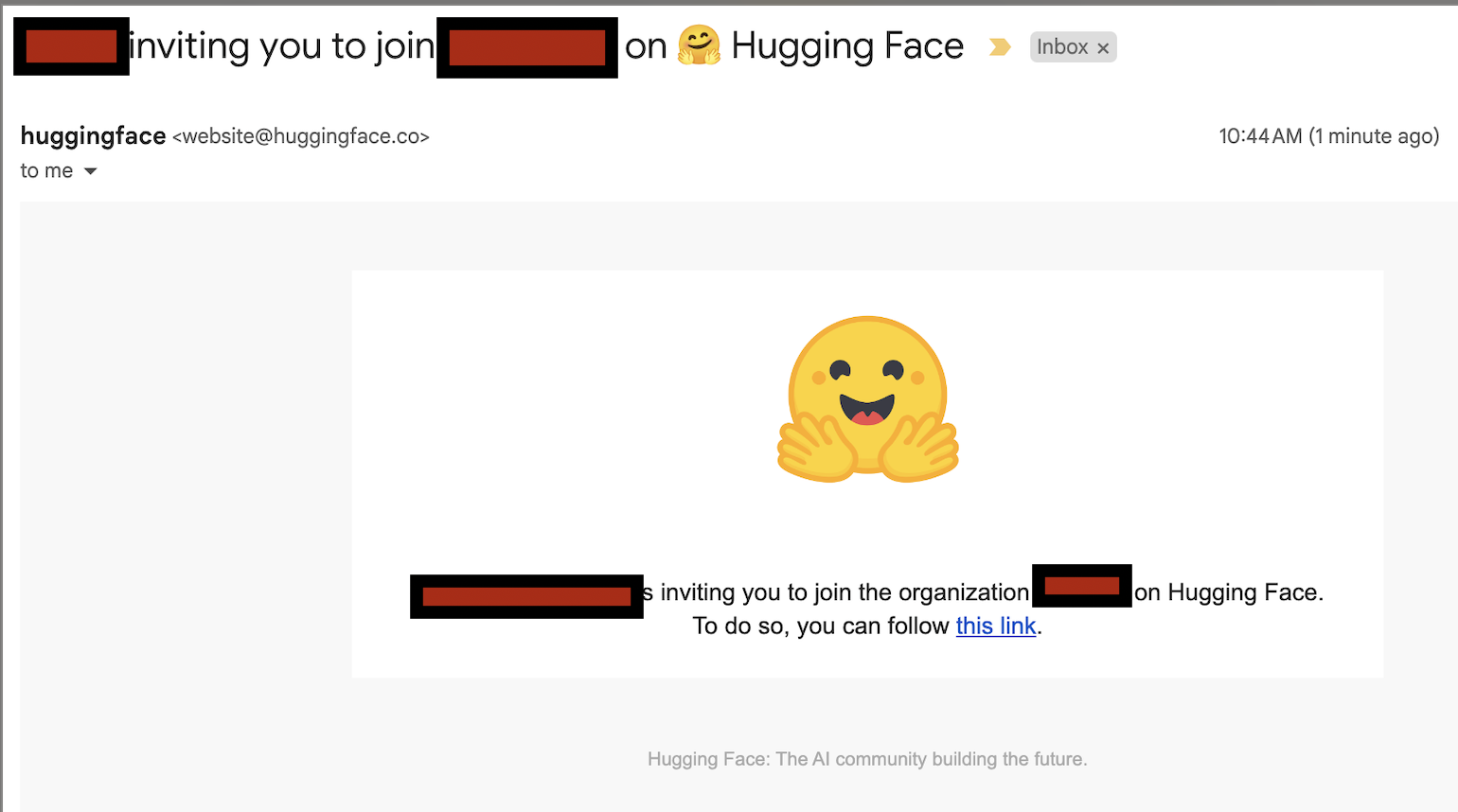 and it looks very official coming from Huggingface and all, not a random gmail.
and it looks very official coming from Huggingface and all, not a random gmail.
(yes, i intentionally revealed one org name and not another)
Secondly, people seem to just try to join their organizations Huggingface organizaiton, they find it on their own, and ask to join.
I let them in, and give them write permissions. Sometimes they make public or private repos. It’s alot easier to get malware in a model to execute if somebody gives you a trusted model.
Potential Solutions
- Invite emails should originate from the user who sent them.
- A more aggresive verification process could take place on who is allowed to originate organizations, such as requiring a matching domain email address.
-
Same session, multiple accounts. Myself and peers working this technique typically get lazy and aren’t careful about segregating our squatted organizations and email addresses. We see the same thing in truly malicious situations at my current employer.
- This is a classic anti-abuse detection technique that could be a function of say, the threat intelligence team.
- Model Typosquatting & general watering holes
- Other techniques for compromising pipelines via models.
What I wrote before about typosquats holds true:
Typosquats are a pretty common technique on repositories, there is not a whole lot here notable, but I think Huggingface makes it easier to hide due to their font choices where many letters look quite similar, like 1 and l. It’s a subtle thing, but combined with the challenges in telling one user or org apart from another in a rapidly changing industry, it’s a nice bonus.
Potential Solutions
Taking lessons from attacks on software dependencies, we can look at Pypi. Going beyond malware detection, they looked to implement checks for typosquats of popular repos using logic like calculating Levenschtien distance.
There is a known typosquatting dataset for refence, showing the average distance attackers like to go for:
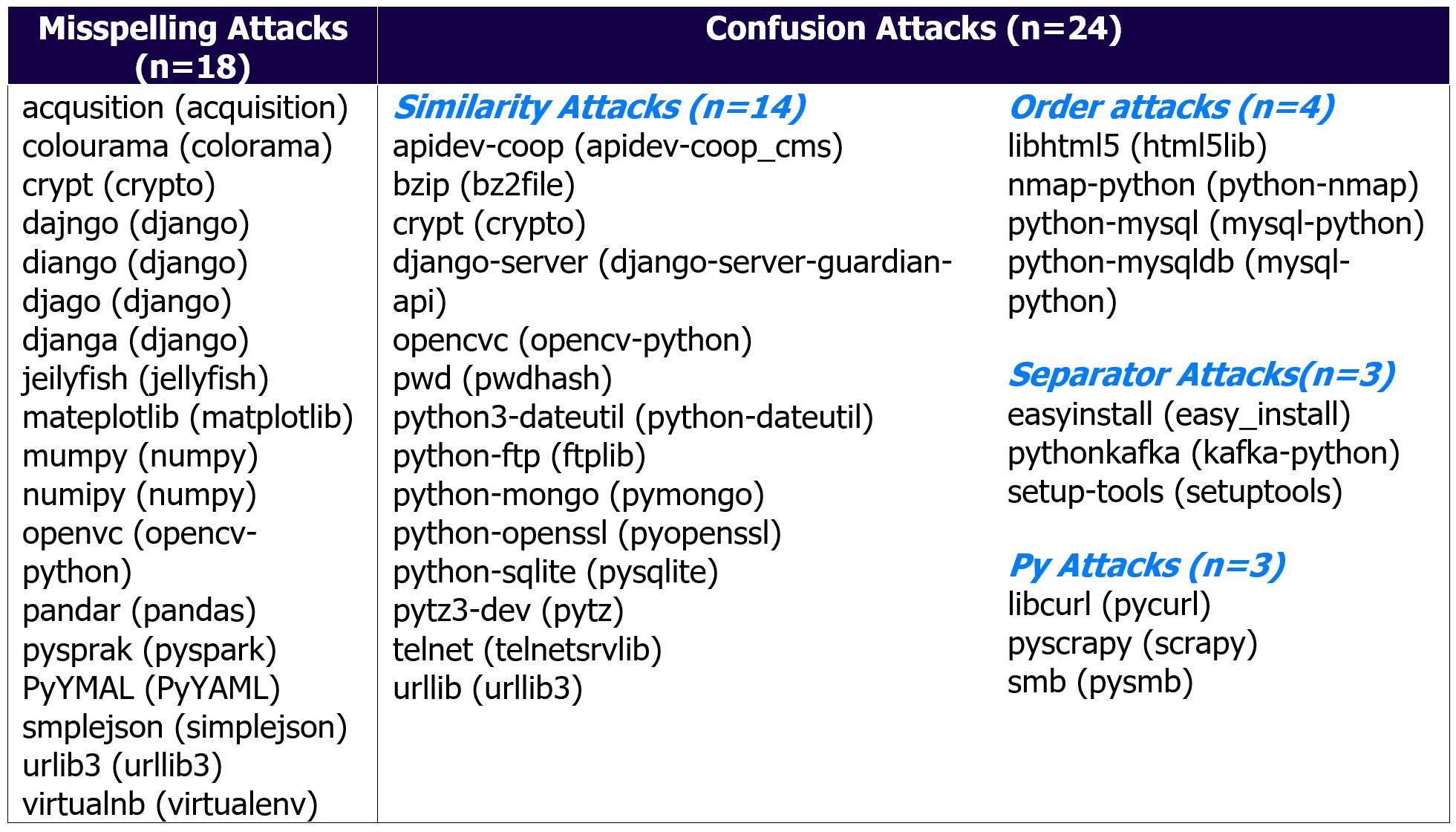
The font choice in the UI for typosquat defense is … not great in my opinion, due to the similarities between letters like i and l. There are many considerations to a font, such as accessibility, brand theme and more. This is a great resource.
What’s next?
On the Horizon, I see more attacks like what NPM experienced, in particular, takeovers of popular packages. Mandatory 2FA rolled out in a similar manner to the steps taken by NPM on popular repositories after a certain usage threshold would be a good thing. I think a lot of the ‘malicious’ packages on HF right now are bounty hunters and red teamers, truly malicious people will target existing users and replace their models because that is the most blantanly obvious way to have alot of success with this technique if ethics aren’t a concern. NPM package takeovers being such a common attack a few years ago is evidence of this.
Summary
Safe tensors is awesome, so is scanning for malicious models. But we also need to take a look at a range of factors ranging from design to product features which enable malicious models (or poisoning attacks) to be successful. Features which allow attackers to represent themselves as Huggingface or other organizations being the top priority, followed by taking lessoned learned from NPM and applying them proactively.